Limulus Software
The following is a list of basic cluster RPMS that will be included in the software stack. The base distribution will be Scientific Linux.
- Scientific Linux V6.3 - RHEL work alike distribution
- Warewulf Cluster Toolkit - Cluster provisioning and administration (V3.1)
- PDSH - Parallel Distributed Shell for collective administration
- Whatsup - A cluster node up/down detection utility
- Open Grid Scheduler - previously Sun Grid Engine Resource Scheduler
- Ganglia - Cluster Monitoring System
- GNU Compilers (gcc, g++, g77, gdb) - Standard GNU compiler suite
- Modules - Manages User Environments
- PVM - Parallel Virtual Machine (message passing middleware)
- MPICH2 - MPI Library (message passing middleware)
- OPEN-MPI - MPI Library (message passing middleware)
- Open-MX - Myrinet Express over Ethernet
- ATLAS - host tuned BLAS library
- OpenBLAS - optimized BLAS library (previously Goto library)
- FFTW - Optimized FFT library
- FFTPACK - FFT library
- LAPACK and BLAS - Linear Algebra library
- ScaLAPACK - Scalable Linear Algebra Package
- PetSc Scalable PDE solvers
- GNU GSL - GNU Scientific Library (over 1000 functions)
- PADB - Parallel Application Debugger Inspection Tool
- Julia - Easy To Use High Performance Parallel Scientific Language
- Userstat - a "top" like job queue/node monitoring application
- Beowulf Performance Suite - benchmark and testing suite
- relayset - power relay control utility
- ssmtp - mail forwarder for nodes
Automatic Power Control
One key design component of the new Limulus Case is software controlled power to the nodes. This feature will allow nodes to be powered-on only when needed. As an experiment, a simple script was written that monitors the Grid Engine queue. If there are jobs waiting in the queue, nodes are powered-on. Once the work is done (i.e. nothing more in the queue) the nodes are powered off).
As an example, an 8 core job was run on the Norbert cluster (in the Limulus case). The head node has 4 cores and each worker node has 2 cores for a total of 10 cores. An 8 node job was submitted via Grid Engine with only the head node powered-on. The script noticed the job waiting in the queue and turned on a single worker node to give 6 cores total, which were still not enough. Another node was powered-on and the total cores reached 8 and the job started to run. After completion, the script noticed that there was nothing in the queue and shutdown the nodes.
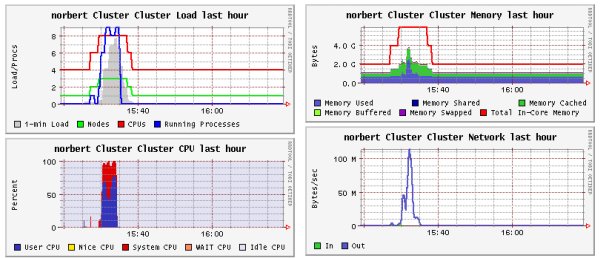
To see how the number of nodes changes with the work in the queue, consider the Ganglia trace below. Note that the number of nodes in the cluster load graph (green line) changes from 1 to 2 then 3 then back down to 1. Similarly the number of CPUs (red line) raises to 8 then back to down to 4 (the original 4 cores in the head node). Similar changes can be seen in the system memory.

Attachments
-
Ganglia-sge-control3-600x258.jpg
 (52.6 KB) -
added by admin 15 years ago.
(52.6 KB) -
added by admin 15 years ago.